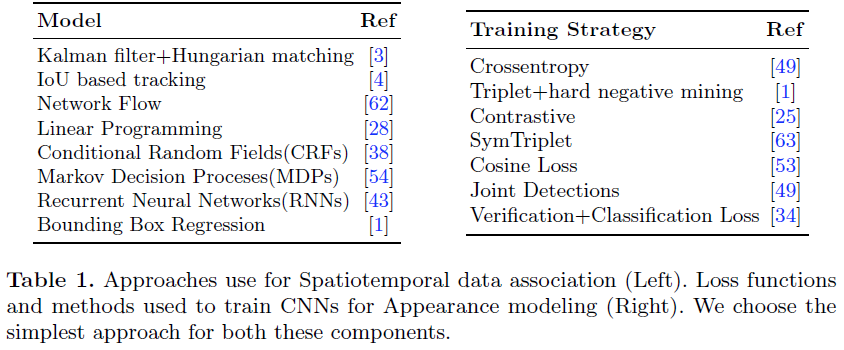
Simple Unsupervised Multi-Object Tracking
主要贡献
-
标注MOT数据集往往费时费力。通过使用一个非监督的ReID 网络,an unsupervised re-identi cation network,无需对数据集进行标注。
-
输入的无标签视频首先通过SORT来生成标签,随后用交叉熵损失来训练SimpleReID网络,与全监督的结果相当。
-
与CenterTrack相结合可以达到SOTA的结果。
简介
MOT大体可分为两类
- A spatio-temporal association model which associates boxes in nearby frames to create clusters of tracklets
- A re-identi cation model which associates tracklets over larger windows to deal with complexities in tracking such as occlusions and target interactions.
训练ReID模型需要大量标注好的数据
在MOT15中标注6min的视频需要22h
通过两步来处理无监督的数据
- 首先基于未标注的视频和对应的检测框集,利用SOTA的追踪器来获得追踪的标签。
- 训练ReID网络来预测标签。
优点
- 比naive ReID 效果更好,更容易与现有的追踪器相结合。
- 与全监督的版本性能相当,而且在不同的数据集,追踪器,检测器上有很好的的性能一致性。
- 与在单张图片上训练的CenterTrack相结合可以实现SOTA
simple unsupervised ReID is sufficient even in crowded scenarios with occlusions and person interactions. 简单的ReID的网络在复杂的场景下也能表现良好。
相关工作
MOT可以被视为图分割问题
Various approaches have been proposed here including using network ows [62], graph cuts [49], MCMC [60] and minimum cliques [61] if the entire video is provided beforehand (batch processing).
In scenarios where we get frame-by-frame input, Hungarian matching [53,3], greedy matching [69] and Recurrent Neural Networks [15,43] are popularly used models for sequential prediction (online processing).
association metrics/cost functions 相关矩阵可以通过时域-空域信息或者ReID获得
Spatiotemporal relations: IoU,Kalman f ilter, Recurrent Neural Networks,
目标检测和单目标追踪可以被视为是非监督的
Recent approaches leverage appearance-reliant pre-trained bounding box regressors from object detection [1] or single object tracking [56,11] pipelines to regress the bounding box in the next frame. Since most of the above models are unsupervised (requiring no tracking annotations), they complement our work and can be incorporated with our proposed approach for creating efficacious unsupervised trackers.
ReID across multiple cameras: 大量标注好的多摄像头数据集使得基于CNN的ReID模型表现良好,对追踪而言重匹配的数据量没有那么大,所以没必要使用复杂的ReID模型。
ReID for monocular 2D tracking: 比较CNN提取的特征是ReID在追踪领域常用的方法
方法
Framework: Learning by generating tracking labels
Generating labels:
首先未标注的视频通过现有的检测器来获得目标的bbox,通过非监督的时空相关算法来获得短时间的目标追踪轨迹。(set of associated detections of the same person over time).
最终可以获得带有许多噪音的标注。
Training ReID models:
两个假设
- 每段视频都是相互独立的,每两段视频间没有ID相同的目标
- 每段视频中的目标都是相互独立的,即每条轨迹有且仅有一个独立的ID
每段轨迹都可以被视为一个ID下对应的class,从而可以训练ReID网络。
物检测,误跟踪,遮挡等现象可能会影响假设2.
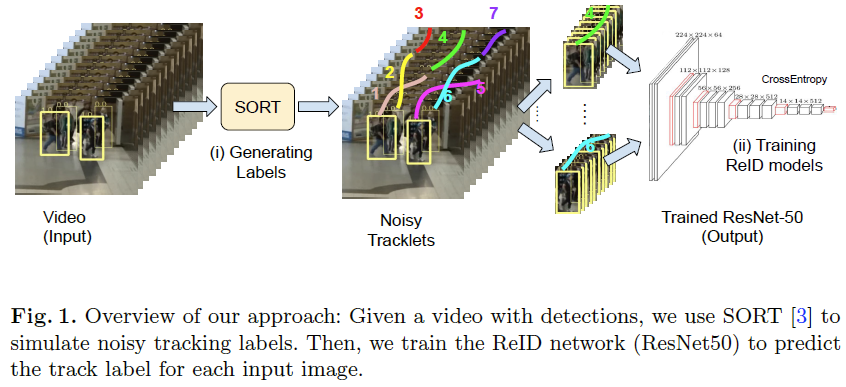
Our method
In step (i), we only utilize the bounding boxes and use Kalman ltering combined with Hungarian matching to simulate labels. Since we use no appearance information, our tracking labels are noisy.
In step (ii), we proceed by making both the aforementioned assumptions that no two videos or tracklets share common labels. We assign a unique label to each tracklet and train a network with cross-entropy loss to predict this label given any image from that tracklet.
In CenterTrack, we extract tracks using its unsupervised model and re ne it with our ReID network using a DeepSORT framework
simpler choices alone are sufficient to match the performance of supervised networks.
实验
- 非监督的追踪器可以达到SOTA的水平
- 非监督的ReID可以替代主流MOT算法中监督学习的部分
- 使用更好的检测器对于非监督模型的提升并不明显
实验主要基于MOT16, MOT17数据集。
We obtain our SimpleReID model by training a ResNet50 [17] backbone popularly used by trackers for a fair comparison. We train the model with tracklets generated by SORT [3] on the PathTrack [36] dataset to test generalization to unseen MOT16/17 data.
使用PathTrack作为训练集 在整个MOT17 训练集,测试集上进行分析。
The submitted tracker consists of our proposed SimpleReID model incorporated with CenterTrack [69] for bounding box regression using public detections.
while CenterTrack is a good detector, it cannot maintain long tracks which is compensated by using our appearance features for Re-identi cation.
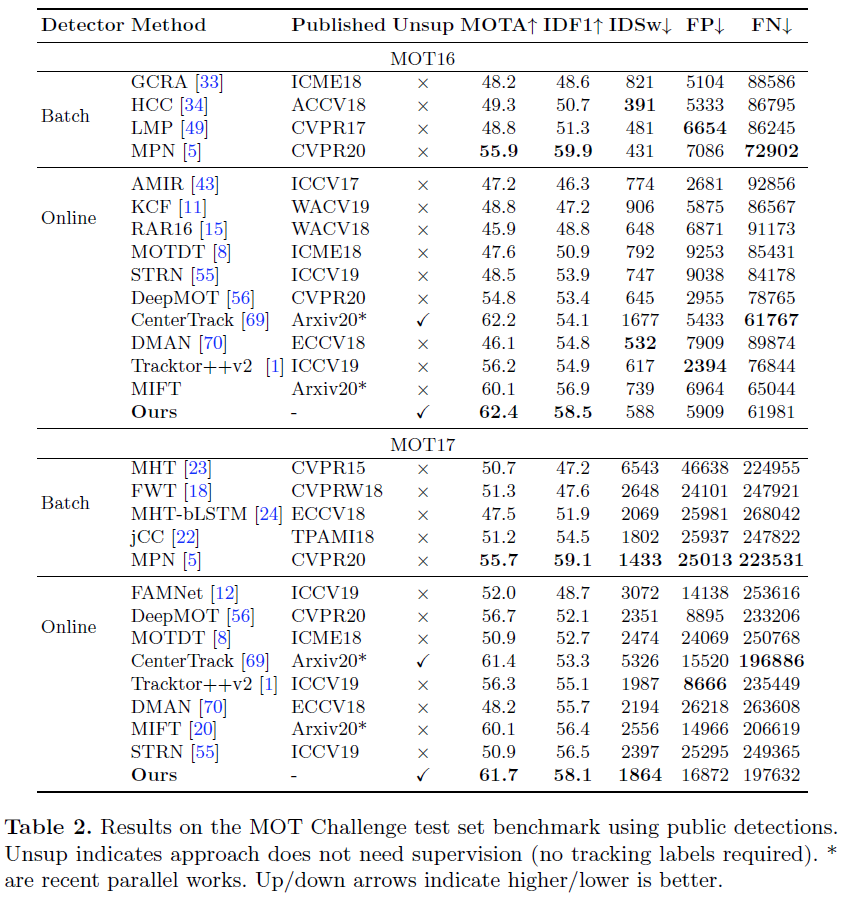
Past literature [49,34] indicates that unsupervised ReID is unlikely to excel in crowded scenarios due to the complexities of tracking in such scenes.
之前的研究表示非监督的ReID不太可能解决复杂场景下的问题。本文则证明了非监督ReID在不同场景下的鲁棒性
(i) We show that the test performance of SimpleReID (on unseen videos) is equivalent to that of a supervised ReID model, on its training set itself。
在未见过的视频中监督,非监督的性能相同
(ii) We show that SimpleReID achieves the above desiderata even with simple trackers which are highly reliant on the ReID component.
SimpleReID 在极度依靠ReID的稳健性的追踪算法中表现良好。
Limits of unsupervised ReID:
We perform experiments across various weaker scenarios such as having no ReID, or using pretrained-ImageNet as-is, and show that these perform signi cantly worse than SimpleReID - proving that SimpleReID is important to match supervised performance.
与监督的ReID算法进行比较。
We rst train another recent supervised tracker, Tracktor++v2[1], which uses bounding box regression along with a supervised ReID model to predict the position of an object in the next frame.
We train the supervised ReID model on the training data for MOT16/ MOT17 and then benchmark the performance on the same training set. In contrast, this data is new to our SimpleReID models, i.e., have not seen these videos previously.
in Table 3. We observe that using ImageNet-pretrained ReID somewhat improves IDF1 scores compared to using no ReID network at all, but fails to achieve the upper bound by a considerable margin. Our SimpleReID approach successfully recovers the remaining performance gap. This is achieved consistently across different variations.
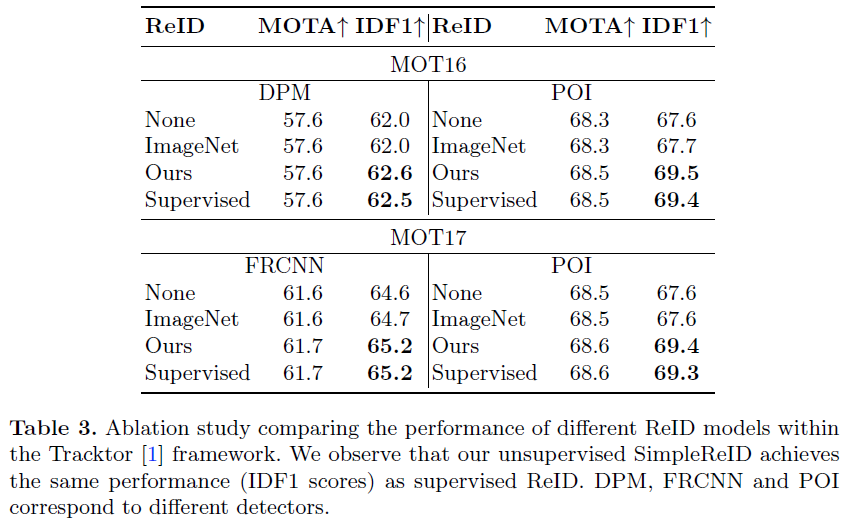
ReID-reliant unsupervised tracking:
Due to the low dependence of Tracktor on its ReID model, one may argue that it might not be the best framework for evaluation of ReID models in tracking.
由于上述算法对ReID的依赖度较低,本文对极度依赖ReID的追踪算法也进行了评估。
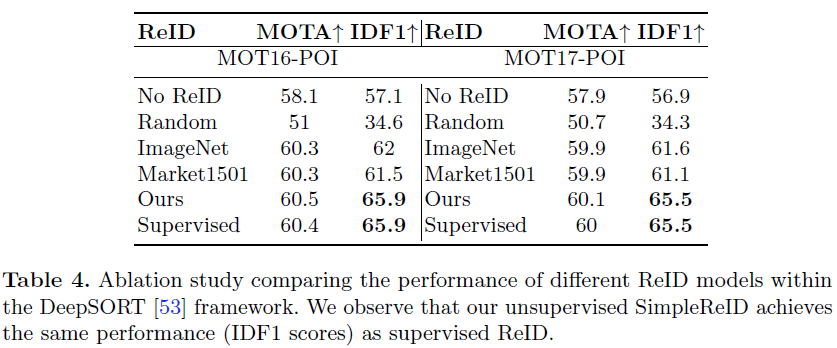
Hence, we also perform the same experiments on a popular tracker DeepSORT [53] that is highly reliant on the ReID model used, since the only visual features it receives is from the ReID network. We replace the supervised ReID model used in DeepSORT with different ReID methods and tabulate results in Table 4.
First, we observe that replacing supervised ReID with random features causes a severe drop in performance over supervised counterpart, with MOTA score decreasing by 9.4% and IDF1 decreasing by 31.3%, demonstrating the degree of reliance on ReID in the DeepSORT framework. When substituted with features from an ImageNet-pretrained ResNet, we get a similar result: a signi cant improvement over SORT, yet much lower than supervised ReID performance. We further benchmark with a supervised ReID model trained on Market1501 dataset [65] and observe lower performance compared to the ImageNet-pretrained model, indicating that features learned for cross-camera person-ReID datasets without trajectory annotations do not transfer to multi-object tracking. Lastly, we observe that our unsupervised SimpleReID covers the remaining performance gap, as seen above.
在多摄像头数据集上学习的ReID模型不能很好地迁移到MOT任务上。
需要注意的是DeepSORT值使用了 ReID结构的特征提取部分,前后帧的数据聚合才用的的是卡尔曼滤波和最邻近贪心算法,匈牙利算法。并没有采用ReID的匹配结果。
Scope for improvement in ReID:
We observe that with modern detectors, the gap between SimpleReID and the corresponding oracles is small enough to limit the scope for further improvement.
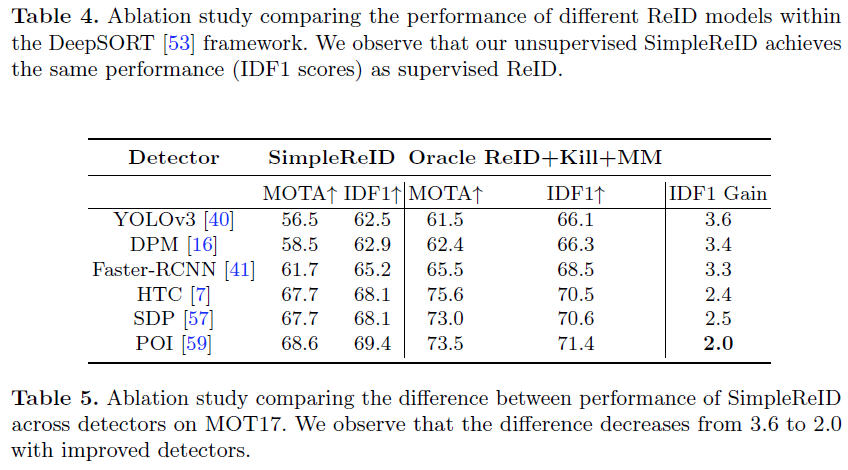
Overall, we conclude that unsupervised SimpleReID counterintuitively matches the limiting performance of supervised counterparts in diffcult MOT scenarios, by leveraging only unlabeled videos.
-
Previous
(CVPR2020)TubeTK: Adopting Tubes to Track Multi-Object in a One-Step Training Model -
Next
Tracking Objects as Points
本文浏览量: 次