Tracking Objects as Points
主要贡献
-
构建了一个更简单,更快,更精确的目标检测与追踪联合算法
we present a simultaneous detection and tracking algorithm that is simpler, faster, and more accurate than the state of the art.
-
CenterTrack, applies a detection model to a pair of images and detections from the prior frame.
-
CenterTrack localizes objects and predicts their associations with the previous frame.
-
CenterTrack is simple, online (no peeking into the future), and real-time.
-
CenterTrack is easily extended to monocular 3D tracking by regressing additional 3D attributes.
简介
Tracking-by-detection, These models rely on a given accurate recognition to identify objects and then link them up through time in a separate stage.
Recent work on simultaneous detection and tracking [1, 8] has made progress in alleviating some of this complexity.
每个目标被描述为bbox的中心点,中心点会被持续跟踪。

Each object is represented by a single point at the center of its bounding box.
使用CenterNet detector
Specifically, we adopt the recent CenterNet detector to localize object centers.
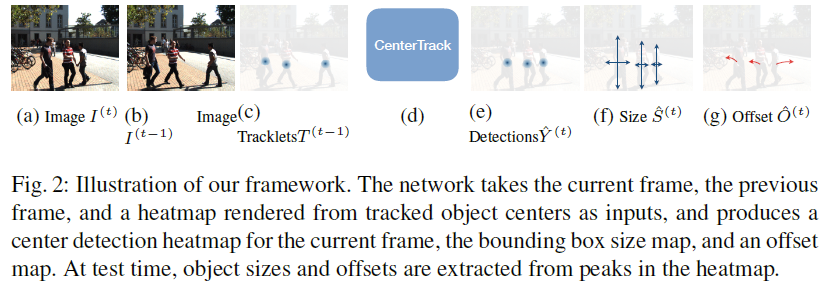
将前后两帧图片和前一帧图片的目标热点图送入网络,网络在输出bbox的同时还会输出当前bbox中心点位置和上一帧同一目标中心点位置的差值。
We condition the detector on two consecutive frames, as well as a heatmap of prior tracklets, represented as points. We train the detector to also output an offset vector from the current object center to its center in the previous frame.
使用贪心算法将上一帧目标的预测位置和实际检测位置进行匹配。
If each object in past frames is represented by a single point, a constellation of objects can be represented by a heatmap of points
point-based tracking simplifies object association across time. A simple displacement prediction, akin to sparse optical flow, allows objects in different frames to be linked.
由于模型倾向于直接输出之前的结果而招致模型的训练损失过小,或者反映为模型拒绝学习追踪过程。所以在训练时采用了具有侵略性的数据增强算法。甚至可以直接在静态图片上训练。
该算法只能关联上下两帧之间的目标,无法实现出现遮挡或消失之后的跟踪恢复。
舍弃这部分的性能来换取模型的简易型,短时追踪的精度与速度。
相关工作
Tracking-by-detection. 通常来说需要额外的特征提取网络来进行前后帧的数据匹配。检测与追踪相分离。
Joint detection and tracking. 将检测器与追踪器合二为一
Motion prediction. Early approaches [2,47] used Kalman filters to model object velocities. Our center offset prediction is analogous to sparse optical flow, but is learned together with the detection network and does not require dense supervision.
Heatmap-conditioned keypoint estimation. A rendered heatmap of prior keypoints [4, 11, 29, 44] is especially appealing in tracking for two reasons. First, the information in the previous frame is freely available and does not slow down the detector. Second, conditional tracking can reason about occluded objects that may no longer be visible in the current frame. The tracker can simply learn to keep those detections from the prior frame around.
3D object detection and tracking.
前置知识



Tracking objects as points

两个挑战
- 逐帧找到所有的目标物体,包括被遮挡的物体
- 间前后两帧的目标匹配起来
Tracking-conditioned detection

Association through offsets


Training on video data

Training on static image data

End-to-end 3D object tracking

实验
略
-
Previous
Simple Unsupervised Multi-Object Tracking -
Next
Multiple People Tracking by Lifted Multicut and Person Re-identification
本文浏览量: 次